If you turn on OCR, Gmail converts the image attachment to text, detects the credit card number, and moves the message to quarantine. Note: OCR doesn’t scan images embedded in attached files, such as Adobe PDF or Microsoft Word documents. And, it’s not always 100% accurate.
Scanning documents into images can be time-consuming as it requires manual input. OCR saves individuals and businesses time and money by converting images into text data that is able to be read by other business software.
Also, a good OCR software should have a user-friendly interface and be easy to use to ensure smooth usage. Data cleansing and formatting are also important components to consider when selecting OCR software. The software should be able to effectively cleanse and format data to ensure data quality and consistency.
How Do I Know if a PDF has OCR Functionality? There are several ways to check whether your PDF has OCR functionality. Open the PDF and check whether you can search for a word in the file or whether you can select any of the text. If you cannot search in the PDF or select text, it is probably just a scanned image.
How to Download OCR Library For Image to Text Convert ?
To convert an image to text using PHP, you can utilize Optical Character Recognition (OCR) libraries. One popular library for this purpose is Tesseract OCR. Here’s an example of how you can use Tesseract OCR to convert an image to text:
Tesseract OCR. Here’s an example of how you can use Tesseract OCR to convert an image to text:
- Install Tesseract OCR on your server. You can follow the installation instructions specific to your operating system from the official Tesseract OCR documentation.
- Install the Tesseract OCR PHP extension. You can use the following command to install it via Composer:
- Use the following PHP code to perform the image to text conversion:
How to install ocr in vps server ?
To install Tesseract OCR on Ubuntu 22.04, you can follow these steps:
Update the package lists on your server:
Copy
sudo apt update
Install Tesseract OCR and its dependencies:
Copy
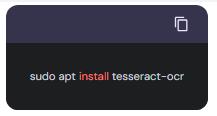
sudo apt install tesseract-ocr
Install additional language data if needed. For example, if you want to install English language support:
The languages currently covered are
- Bengali (ben)
- Gujarati (guj)
- Hindi (hin)
- Kannada (kan)
- Malayalam (mal)
- Meetei Meyak (mni)
- Oriya (ori)
- Punjabi (pan)
- Santali (sat)
- Tamil (tam)
- Telugu (tel)
- English (eng)
Copy
sudo apt install tesseract-ocr-eng
Verify the installation by checking the Tesseract OCR version:
Copy
tesseract –version
This should display the installed version of Tesseract OCR.
Once Tesseract OCR is installed, you can use it in your PHP code as mentioned in the previous response. Remember to include the Tesseract OCR PHP library by requiring the autoload file generated by Composer and set any additional options if needed.
Please note that Tesseract OCR supports various languages, and you can install language data for the specific languages you require.
To use TesseractOCR with PHP to extract text from images containing both Hindi and English languages, you can specify multiple language parameters in the TesseractOCR command. Here’s an example: